Structured Data in SPAs: What Crawlers Actually See
You've spent weeks perfecting your React or Vue app. The user experience is silky smooth, the design is modern, and your structured data is meticulously crafted. Then you check Google Search Console — and your rich results are nowhere to be found.
The culprit is almost always the same: your structured data exists in JavaScript, but crawlers never actually execute it. This is the quiet SEO crisis hiding inside every single-page application (SPA).
The SPA SEO Problem Nobody Talks About
Single-page applications have transformed modern website design. Frameworks like React, Vue, and Angular deliver fast, app-like experiences by rendering content entirely in the browser — a pattern called client-side rendering (CSR).
The problem is that search crawlers were built for a different web — one where the server sent fully formed HTML and structured data was baked right into it. CSR flips that model upside down, and structured data is the first casualty.
How Crawlers Process Web Pages (and Why SPAs Break the Rules)
Traditional crawl pipelines are straightforward: a crawler fetches a URL, receives HTML from the server, parses its content and links, and passes it to the indexer. Structured data embedded in that HTML is parsed immediately.
SPAs break this pipeline at the first step. The HTML a crawler initially receives is essentially an empty shell — usually just a <div id="root"></div> and a bundle of JavaScript. The actual content — including your structured data — doesn't exist yet.
The Rendering Queue: A Hidden SEO Delay
Googlebot does eventually render JavaScript — but not right away. Google uses a two-wave indexing process: the first wave indexes the raw HTML it receives immediately, and the second wave renders the JavaScript, sometimes days or weeks later.
During that gap, your page is indexed without any structured data. Even after rendering, pages sit in a queue behind millions of others. Structured data injected via JavaScript may be perpetually delayed or missed entirely if Googlebot's rendering resources are constrained.
What Other Crawlers Do (Bing, Social Bots, AI Crawlers)
Google is actually the generous exception here. Bingbot, social media link-preview bots (Facebook, Twitter, LinkedIn), and most AI crawlers like GPTBot do not execute JavaScript at all. They read only the initial HTML response and move on.
That means your CSR-injected structured data is completely invisible to them. No review stars on Bing. No rich link previews on LinkedIn. No content for AI training and discovery. The SEO impact extends far beyond Google rankings.
Structured Data 101: Why It Matters for SPAs
Structured data is machine-readable markup that tells search engines what your content means, not just what it says. The three main formats are JSON-LD, Microdata, and RDFa — and they power rich results like review stars, FAQ dropdowns, breadcrumb trails, and event listings.
Rich results consistently earn higher click-through rates than plain blue links. For an SPA-based website design, getting structured data in front of crawlers isn't optional — it's a direct revenue concern.
JSON-LD vs. Inline Microdata in a CSR Context
Google officially recommends JSON-LD because it lives in a <script> tag separate from your content, making it easier to manage and update. Microdata is embedded inline with your HTML elements, which can feel more natural but is harder to maintain.
The critical point is that in a CSR environment, both approaches share the same problem: they only exist after JavaScript executes. The format you choose matters far less than whether crawlers can see it at all.
What Crawlers Actually See: A CSR Reality Check
Here's what a non-rendering crawler receives when it fetches a typical React SPA:
<!DOCTYPE html>
<html>
<head>
<title>My App</title>
</head>
<body>
<div id="root"></div>
<script src="/static/js/main.abc123.js"></script>
</body>
</html>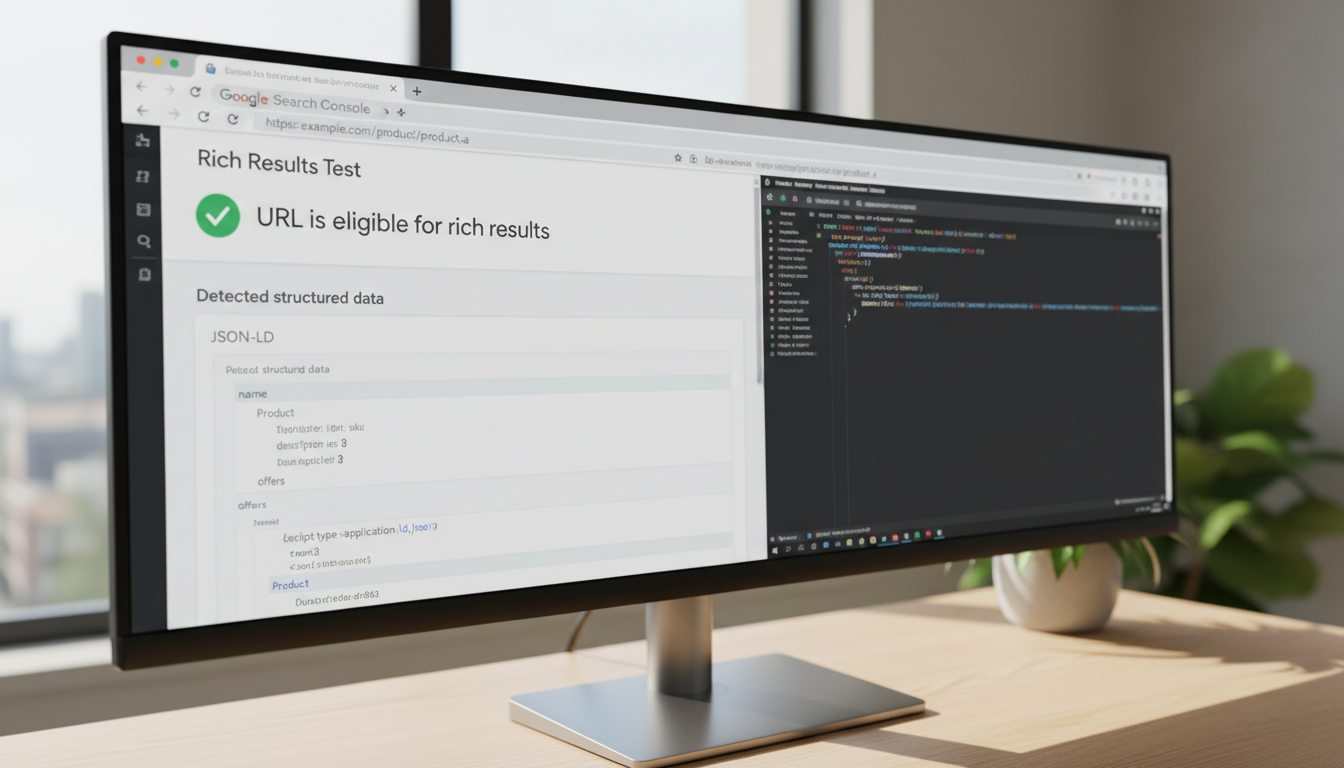
No product schema. No breadcrumbs. No FAQ markup. Just an empty container and a JavaScript bundle the crawler won't execute.
After JavaScript runs in a real browser, that same page might contain 200 lines of rich JSON-LD, fully rendered product details, and dynamic breadcrumb paths. The gap between those two states is exactly where your SEO breaks down.
Tools to Test What Crawlers Really Receive
Before you fix anything, you need to see the problem clearly. Use these tools to audit your current situation:
Google's Rich Results Test — Paste your URL and see exactly what structured data Google can extract.
URL Inspection Tool (Search Console) — Shows the rendered HTML Googlebot actually indexed, including any detected structured data.
Screaming Frog (JS rendering off) — Crawl your site with JavaScript disabled to simulate Bingbot and social crawlers.
curl request — Run
curl -A "Googlebot" https://yoursite.com/pageto see the raw HTML your server returns.Google vs Browser View — A free tool that shows the exact gap between what Googlebot fetches and what your browser renders, side by side.
Solutions: How to Ensure Crawlers See Your Structured Data
Once you've confirmed the gap exists, you have three main strategies to close it. They're ranked here by reliability and long-term sustainability.
Pre-rendering: The Most Reliable Fix
Pre-rendering generates a static HTML snapshot of your SPA page — complete with fully resolved structured data — before any crawler arrives. That snapshot is served instantly to bots, while real users continue getting the full interactive SPA experience.
Services like RndrKit handle this transparently at the CDN/proxy layer. When a crawler hits your site, it receives a fully rendered HTML page with all your JSON-LD intact. You can learn exactly how this works in the RndrKit rendering pipeline documentation. No framework changes, no rebuilding your stack.
Build-time static site generation (SSG) achieves a similar result for sites with predictable content. For dynamic SPAs where content changes frequently, on-demand pre-rendering is the more practical choice.
Server-Side Rendering (SSR): Power with Trade-offs
Server-side rendering runs your JavaScript on the server for every request, sending fully formed HTML — including structured data — in the initial response. Frameworks like Next.js and Nuxt make SSR more accessible than it used to be.
The trade-off is real: SSR adds infrastructure complexity, increases server costs, and can introduce latency under high traffic. For teams already deep into a CSR architecture, it often means significant refactoring. Not a quick win.
Dynamic Rendering as a Stopgap
Dynamic rendering serves pre-rendered HTML to detected bots while serving the normal CSR SPA to human users. Google has stated this is acceptable but describes it as a workaround, not a permanent solution.
It's a reasonable bridge strategy if you're mid-migration to SSR or pre-rendering. The risk is maintaining two rendering pipelines — any discrepancy between what bots and users see can raise cloaking flags if not implemented carefully.
Best Practices for Structured Data in SPA Website Design
Whichever rendering strategy you adopt, these practices will keep your structured data healthy over time:
Always validate after deployment. Run Google's Rich Results Test on every page after a new deploy — structured data errors are easy to introduce silently.
Place JSON-LD in the document
<head>, not the body. It loads earlier and signals intent to parsers more reliably.Invalidate pre-rendered cache on content updates. Stale cached snapshots can serve outdated structured data to crawlers. Automate cache purging when content changes.
Monitor Search Console regularly. The Enhancements section reports structured data errors and warnings per schema type. Review it at least monthly.
Test all crawler types, not just Google. Use tools like the Bot Response Tester to verify how your site responds to Bingbot, social crawlers, and AI bots simultaneously.
Conclusion: Close the Gap Between What Users See and What Crawlers See
The fundamental tension in SPA SEO is simple: your users see a rich, fully rendered experience, but crawlers often see an empty page. Structured data sits right at the center of that gap — it's valuable only when search engines can actually read it.
The good news is that you don't have to tear down your SPA to fix this. Pre-rendering solves the crawler visibility problem without touching your frontend architecture. Start by auditing what crawlers currently see using the tools described above — many developers are shocked by how little structure their "structured data" actually delivers to search engines.
If you'd like a deeper dive into choosing the right approach for your stack, the SSR vs Pre-rendering interactive guide will point you in the right direction based on your specific setup. And if you're ready to close the gap today, RndrKit makes your SPA's structured data visible to every crawler — Google, Bing, social bots, and AI crawlers alike — without changing a single line of your application code.
Fix your SPA's SEO automatically
RndrKit pre-renders your pages so search engines see fully-rendered HTML.
Start Free Trial